一致性模型
基本概念
正确性(Correctness)
一个系统是由一个状态和一些转换该状态的操作组成的。当系统运行时,它通过一些操作记录从一个状态转换到另一个状态。
例如,状态可以是变量,操作可以是对这个变量的读写。一旦我们将一个变量设置为某个值,比如a,读取它就应该返回a,直到我们再次改变这个值。读取一个变量会返回最近写入的值。我们把这种系统--一个只有一个值的变量--称为寄存器。
这暗示了系统正确性的定义:给定一些规则,这些规则将操作和状态联系起来,系统中的操作记录应该总是遵循这些规则。我们称这些规则为一致性模型。
更正式地说,我们说一个一致性模型是所有允许的操作记录的集合。如果我们运行一个程序,并且它经历了允许集中的操作序列,那么这个特定的执行就是一致的。如果程序偶尔出错,经历了一个不在一致性模型中的操作记录,我们说这个操作记录是不一致的。如果每一个可能的执行都落入了允许的集合中,那么系统就满足了模型。我们希望真实的系统能够满足 "直观正确 "的一致性模型,这样我们就可以写出可预测的程序。
并发(Concurrency)
很多语言支持并发,对于其中的多逻辑线程控制,我们在这里通称为多进程(processes,与操作系统里的进程概念无关)。如果我们运行一个有两个进程的并发程序,每个进程都使用同一个寄存器,那么我们之前的寄存器不变性就会被违反。 多个进程操作同一个寄存器的时候,寄存器成为两个进程之间的协调场所,它们共享状态。
延时(Latency)
在现实条件下,我们的任何操作都不是瞬时的。任何操作都要耗费时间。
不同地点发送消息的延时会导致操作记录的歧义性。消息传播的快慢不同,会导致事件顺序发生得意想不到。
在一个分布式系统中--这个系统中,任何操作的发生是需要时间的--我们必须再次放宽我们的一致性模型,允许这些有歧义的顺序发生。
线性一致性(Linearizability)
假设我们有一个全局状态与每个进程通信;继续假设对该状态的操作是原子性地进行的,那么我们就可以排除很多可能发生的操作。每一个操作在其调用和完成之间的某一时间点上原子化地生效。
我们称这种一致性模型为线性一致性。尽管操作是并发的并且耗时的,但每一个操作都会在某处以严格的线性顺序发生。
"全局状态"不一定是单一节点,操作实际上也不一定是原子的:状态可以被分片在许多机器上,或者发生在多个步骤中--只要从进程的角度来看,外部记录看起来相当于一个原子的、单一的状态。
我们可以使用线性化的原子约束来安全地修改状态。可以定义一个类似于compare-and-set的操作,在这个操作中,如果且仅当一个寄存器当前有某个值时,我们就把这个寄存器的值设置为一个新的值。我们可以使用CAS作为mutexes、semaphores、channel、counters、list、set、map、tree等的共享数据结构的基础。线性化保证了安全地交错进行变更。
此外,线性化的时间界限保证了这些变化在操作完成后对其他参与者可见。于是,线性一致性禁止过时的读,同样禁止了非单调的读。
由于这些强大的约束,可线性化系统更容易推理--这就是为什么它们被选为许多并发编程结构的基础。Javascript中的所有变量都是(独立的)可线性化的;Java中的volatile变量、Clojure中的atoms或Erlang中的process也是如此。大多数语言都有mutexes(互斥)和semaphores(信号量),这些也是可线性化的。强约束的假设产生抢约束的保证。
(线性一致性的约束与保证:1.所有进程的读写操作都以严格的线性顺序发生。2.任意操作虽然耗时,但在操作的调用与完成之间的某个时间点生效且是原子性的。3.所有的读操作,总能返回最近的写操作的值。线性一致性又被称为强一致性或者原子一致性)
但如果我们无法满足这些假设,会发生什么?
顺序一致性(Sequential consistency)
如果我们允许进程在时间上偏斜,使它们的操作可以在调用前或完成后生效--但保留任何给定进程的操作必须按照该进程的顺序进行的约束--我们就会得到一种较弱的一致性:顺序一致性。
序列一致性比线性化产生更多的记录--但它仍然是一个有用的模型:一个我们每天都在使用的模型。例如,当用户将一个视频上传到YouTube时,YouTube会将该视频放入队列中进行处理,然后马上返回一个视频的网页。这时我们实际上不能观看视频,视频上传几分钟后,当视频被完全处理后,才会生效。队列消除了同步行为,同时(取决于队列)保留了秩序。
很多缓存的行为也像顺序一致的系统。如果我在Twitter上写了一条推文,或者发布到Facebook上,它需要时间来渗透到层层缓存系统中。不同的用户会在不同的时间看到我的信息--但每个用户都会按顺序看到我的操作。一旦看到,一篇文章就不应该消失。如果我写了多条评论,它们会按顺序变得可见,而不是失去顺序。
(顺序一致性的约束与保证:1.不要求操作的执行顺序严格按照真实的时间序,2.对不同进程之间的读写操作执行顺序没有任何要求,只需保证执行是原子性即可,3.单一进程内的操作执行顺序以编程中的顺序为准)
因果一致性(Casual consistency)
我们不必强制约束进程中的每个操作的顺序。只有因果相关的操作才必须按顺序发生。
例如,我们可能会说,博客文章上的所有评论必须以相同的顺序出现在每个人的面前,并坚持任何回复只有在它所回复的文章可见之后,才会对一个进程可见。如果我们把那些像 "我依赖于操作X "这样的因果关系编码为每个操作的显式部分,数据库就可以延迟使操作可见,直到它拥有所有操作的依赖关系。
这比对来自同一进程的每个操作进行排序要弱--来自同一进程的具有独立因果链的操作可以以任何相对的顺序执行--但可以防止许多不直观的行为。
可序列化的一致性(Serializable consistency)
如果我们说操作记录等同于按某个单一原子顺序发生的历史--但对调用和完成时间只字不提,我们就会得到一个被称为可序列化的一致性模型。这个模型比你预期的要强得多,也弱得多。
因为序列化允许任意重新排序操作(只要顺序看起来是原子的),所以它在实际应用中不是特别有用。大多数声称提供序列化的数据库实际上提供了强序列化,它与线性化有相同的时间界限。更复杂的是,大多数SQL数据库所说的serializable一致性级别实际上意味着一些较弱的东西,比如可重复读取、游标稳定性或快照隔离。
Linearizability VS. Serializability
Linearizability: single-operation, single-object, real-time order.
Serializability: multi-operation, multi-object, arbitrary total order.
一致性的代价(Consistency comes with costs)
我们说过,"弱 "一致性模型比 "强 "一致性模型允许更多的操作记录。例如,线性化保证操作发生在调用和完成时间之间。然而,强加顺序约束需要协调。通俗地讲,我们排除的记录越多,系统中的参与者就必须越小心谨慎且通信频繁。
你可能听说过CAP定理,该定理指出,给定一致性、可用性和分区容忍度,任何给定的系统最多可以保证其中两个属性。虽然Eric Brewer的CAP猜想是用非正式的术语表述的,下面是更精确的定义:
一致性意味着可线性化,特别地,可以是可线性化的寄存器。寄存器等同于其他系统,包括集合、列表、地图、关系数据库等等,所以该定理可以扩展到涵盖所有种类的可线性化系统。
可用性是指对非故障节点的每个请求都必须成功完成。由于网络分区被允许持续任意长的时间,这意味着节点不能简单地将响应推迟到分区愈合之后。
分区容忍意味着分区可以发生。当网络可靠时,提供一致性和可用性很容易。当网络不可靠时,提供这两方面的服务是不可能的。如果你的网络并不完全可靠--事实就是如此--你就不能选择CA。这意味着,所有实际的商用分布式系统最多可以保证AP或CP。
"等等!"你可能会惊呼。"线性化不是一致性模型的终极目标! 我可以通过提供顺序一致性,或者序列化性,或者快照隔离来绕过CAP定理!"
这是真的,CAP定理只是说我们不能构建完全可用的可线性化系统。问题是,我们还有其他的证明,这些证明告诉我们,你无法构建具有顺序性、可序列化、可重复读取、快照隔离或游标稳定性的完全可用系统--或者任何比这些更强的模型。在这张来自Peter Bailis的Highly Available Transactions论文的地图中,红色阴影的模型不能完全可用。
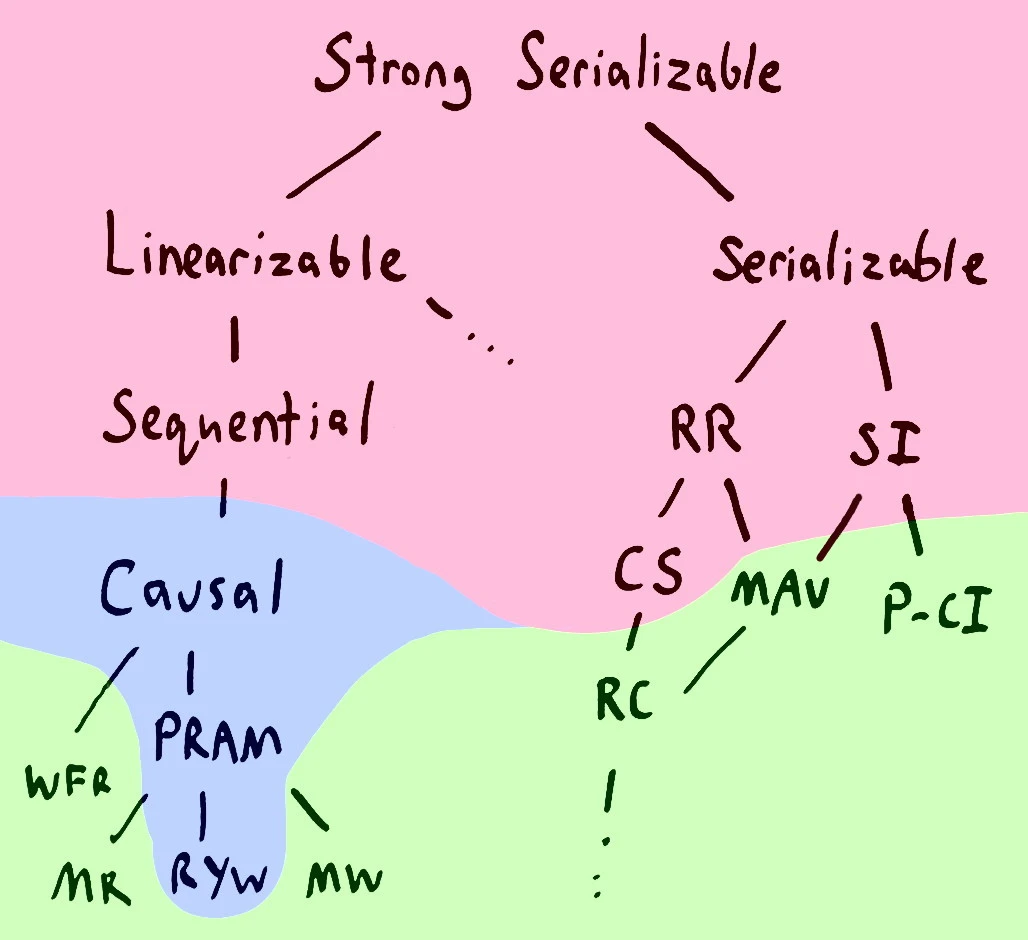
如果我们放宽可用性的概念,比如客户端节点必须始终与同一个服务器对话,那么某些类型的一致性就可以实现。我们可以提供因果一致性、PRAM和读你所写的一致性。
如果我们要求完全的可用性,那么我们可以提供单调的读、单调的写、读已提交、单调的原子视图等等。这些都是Riak和Cassandra等分布式存储,或者ANSI SQL数据库在较低隔离设置上提供的一致性模型。这些一致性模型并不像之前那样保证线性顺序,而是以批处理或网络的方式提供了部分顺序。这些顺序之所以是局部的,是因为它们接纳了更广泛的操作记录。
一种混合方法(A hybrid approach)
一些算法的安全性依赖于线性化。例如,如果我们想建立一个分布式的锁服务,就需要线性化。如果没有硬性的时间边界的话,我们就可以持有一个未来的或过去的锁。另一方面,很多算法不需要线性化。例如,最终一致的集合、列表、树和地图,即使在 "弱 "一致性模型中也可以安全地表达为CRDT(Commutative Replicated Data Types)。
更强约束的一致性模型也往往需要更多的协调--更多的消息来回传递,以确保它们的操作以正确的顺序发生。这不仅意味着可用性较低,而且还导致更高的延迟。这就是为什么现代CPU内存模型默认情况下是不可线性化的--除非你明确说出来。现代CPU会在多核之间重排内存操作的顺序,甚至更糟。虽然指令操作更难推理,但性能优势是惊人的。在不同地理位置上部署的分布式系统,数据中心之间有数百毫秒的延迟,通常会做出类似的权衡。
所以在实践中,我们使用混合数据存储,将不同一致性模型的数据库混合在一起,以实现我们的冗余、可用性、性能和安全目标。尽可能采用 "较弱 "的一致性模型,以实现可用性和性能。必要时采用 "较强 "的一致性模型,因为所表达的算法要求更严格的操作顺序。
例如,你可以将大量数据写入S3、Riak或Cassandra,然后将这些数据的指针,线性地写入Postgres、Zookeeper或Etcd。有些数据库支持多种一致性模型,比如关系型数据库中的可调整隔离级别,或者Cassandra和Riak的可线性化事务,这有助于减少使用的系统数量。不过底线是:任何说自己的一致性模型是唯一正确选择的人,很可能是想推销什么。鱼和熊掌不可兼得。
其他
参考翻译 https://aphyr.com/posts/313-strong-consistency-models ,在理解基础上稍微做了修改。